
Tom Cao
Pattern-based anomaly detection catches gradual attacks and memory leaks that static thresholds miss completely.
The story: It's 3 AM and your phone buzzes. "CPU at 85%." Your brain immediately starts calculating - production database or staging environment? Customer-facing service or internal tool? Wake the team or wait until morning?
If you're a DevOps engineer, this mental gymnastics routine happens multiple times per week. You've become a human pattern-recognition engine, carrying critical system knowledge in your head. But what happens when you're unavailable? When a new team member joins? When subtle patterns slip through your mental filters?
The crypto exchange I worked at learned this lesson the hard way. Twice.
When Human Pattern Recognition Fails
At the crypto exchange, we managed everything from WordPress sites to Java applications, multiple database types, and complex trading systems. The Telegram alerts never stopped flowing. Over time, I developed an internal classification system: database alerts meant immediate action, staging environment spikes could wait, and minor service fluctuations were usually safe to ignore.
This worked until it didn't.
The WordPress Hack: Missing the Gradual Attack
Our WordPress site got compromised, but the attack didn't happen overnight. The warning signs were there:
- RAM usage gradually increasing over several hours
- Disk I/O showing unusual spikes
- Response times becoming inconsistent
- Strange entries appearing in logs
Each metric looked "normal enough" when viewed in isolation. My mental filter processed these as acceptable fluctuations. It wasn't until network traffic spiked dramatically that we realized we were under attack.
By then, the damage was spreading.
The Memory Leak That Killed Servers
Another incident involved a code deployment that introduced a memory leak manifesting every five minutes. CPU and memory would spike, disk I/O would increase, then stabilize. Rinse and repeat.
For hours, I dismissed these patterns. "It's within normal range," I thought. "Probably just background processes."
Then the servers started dying.
The recurring five-minute pattern was obvious in retrospect, but human brains aren't designed to spot re-curring degradation when we're looking at current values instead of temporal trends.
The Fatal Issue: Static Thresholds Miss What Matters
Both incidents shared a common problem. Traditional monitoring relies on static thresholds: "Alert when response time exceeds 1000ms" or "Flag when CPU hits 90%."
But this approach misses the patterns that indicate real problems:
- Gradual degradation: The WordPress hack showed steady resource increases that never breached individual thresholds
- Re-curring issues: The memory leak repeated every five minutes but stayed within "acceptable" ranges
- Context blindness: RAM increases during low-traffic hours should have been suspicious but looked normal in isolation
- Pattern correlation: Multiple related metrics deteriorating together got missed
We needed monitoring that understood behavior, not just current states.
What Intelligent Anomaly Detection Actually Looks Like
Smart anomaly detection works differently. Instead of asking "Is response time above 1000ms?", it asks "Are 80% of requests showing degraded performance within a 15-minute window?"
This approach would have caught both crypto exchange incidents:
For the memory leak: When 80% of requests consistently showed degraded performance every five minutes, pattern-based detection would have fired alerts long before servers crashed.
For the WordPress hack: Gradual RAM increases affecting a significant percentage of requests during low-traffic periods would have triggered early warnings, not final damage alerts.
How Bubobot Implements Pattern-Based Protection
Bubobot uses two approaches to catch problems before they impact your business:
Threshold Method: Immediate Pattern Protection
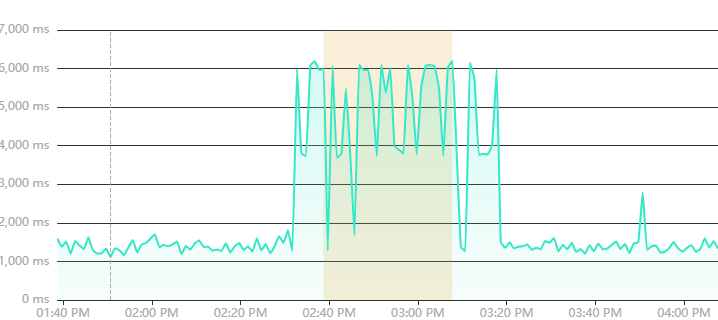
Configure percentage-based detection that makes sense for your environment:
- Alert when 80% of response time checks exceed 5000ms within 15 minutes
- Flag when 70% of availability checks show degradation over a 10-minute window
- Detect when 90% of requests show increased latency during typically stable periods
This catches obvious patterns immediately without requiring any learning period.
AI Method: Learning Your Normal
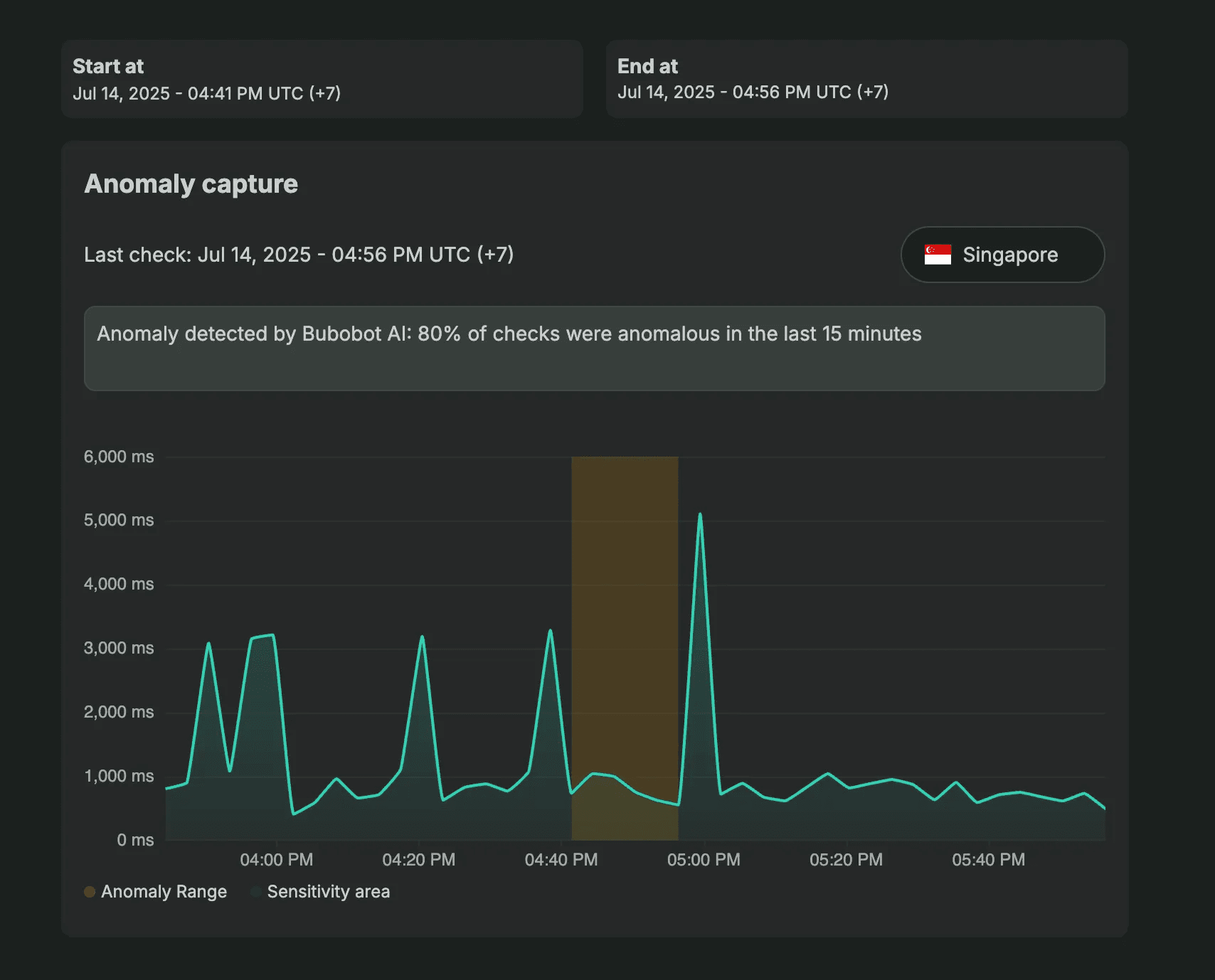
After 14 days of observing your system, Bubobot's AI builds custom baselines for your specific environment. It learns:
- Your normal traffic patterns throughout the day
- How your system behaves during deployments
- Seasonal variations in performance
- The relationship between different metrics in your stack
The AI method would have flagged the WordPress hack within hours. Gradual RAM increases during typically low-resource periods would have been immediately identified as anomalous behavior for that specific time and context.
Adaptive Intelligence: Staying Current
As your system evolves—new deployments, traffic growth, infrastructure changes—Bubobot retrains its models. You don't get stuck with outdated baselines that become increasingly irrelevant.
This prevents the common problem where anomaly detection becomes useless after system changes, forcing teams back to manual monitoring.
Why This Matters for Your Business
The crypto exchange incidents taught me that pattern blindness has real costs. The WordPress hack could have been stopped hours earlier, preventing data exposure and customer trust issues. The memory leak could have been caught before servers crashed, avoiding trading disruptions and potential revenue loss.
But the bigger lesson was about team scalability. In high-growth environments, you can't keep critical monitoring knowledge locked in individual minds. What happens during vacations? When team members leave? When you need to onboard new engineers quickly?
Pattern-based anomaly detection preserves institutional knowledge in software rather than human memory. It scales with your team and systems instead of creating bottlenecks.
Getting Started: From Reactive to Predictive
Moving to intelligent anomaly detection doesn't require ripping out existing systems. Here's the practical approach:
Start with Critical Services
Focus percentage-based detection on services that directly impact revenue: API endpoints, payment systems, user authentication. Configure rules like "Alert when 80% of response time checks exceed normal ranges within 15 minutes."
Layer on AI Learning
Enable AI-based detection for broader system coverage. The 14-day learning period builds custom baselines while your existing monitoring continues protecting critical services.
Gradual Migration
Add pattern-based detection to non-critical services first to validate behavior, then expand to revenue-generating systems once you're confident in the approach.
Team Adoption
Configure escalation policies that match your team structure and business priorities. Trading systems get immediate escalation; internal tools can wait for business hours.
The Pattern Recognition You Need
If your monitoring strategy still relies on static thresholds and human pattern recognition, you're gambling with your uptime. The question isn't whether you'll miss something important—it's when.
The technology exists to catch the subtle patterns that precede major incidents. Percentage-based logic identifies re-curring problems before they cascade. AI learning spots behavioral changes that static thresholds miss. Adaptive intelligence keeps detection accurate as your systems evolve.
Both crypto exchange incidents would have been prevented with pattern-aware monitoring. The gradual WordPress attack would have triggered alerts when resource usage patterns deviated from normal low-traffic behavior. The memory leak would have been caught the moment 80% of requests showed the recurring five-minute degradation pattern.
The choice is simple: implement intelligent anomaly detection now, or wait for the next incident to teach you why pattern recognition belongs in software, not human memory.
Ready to stop missing patterns that matter? Discover how pattern-based anomaly detection can protect your systems before problems impact your business.



