
Downtime destroys businesses, but a strong escalation policy ensures your systems stay running and your team responds fast. Without proper escalation, critical alerts can sit unnoticed for hours, turning minor issues into major outages.
Downtime destroys businesses, but a strong escalation policy ensures your systems will run and your team responding. This Guide shows you how to develop an effective uptime strategy for SMEs with high-impact systems that integrate practical tips, AI tools such as Bubobot and DevOps/IT Admin steps.
1. Why Escalation Policies Matter for Uptime & Incident Response
Structured escalation policies transform critical situation into coordinated responses. When your website crashes during peak traffic, a predefined escalation path—automatically alerting a DevOps engineer within 5 minutes—cuts downtime from hours to minutes.
The poor escalation are costly. Picture a server failing during your biggest sales day. Without escalation path, that critical alert sits unnoticed for 30 minutes while revenue vanishes. Uptime monitoring tools like Bubobot eliminate this risk by triggering instant escalations, getting your team fixing issues within 10 minutes—often before customers notice.
Escalation policies function as your rapid-response insurance, ensuring no critical alert gets buried while protecting your business continuity. Website uptime monitoring becomes meaningless without the escalation backbone to act on its alerts.
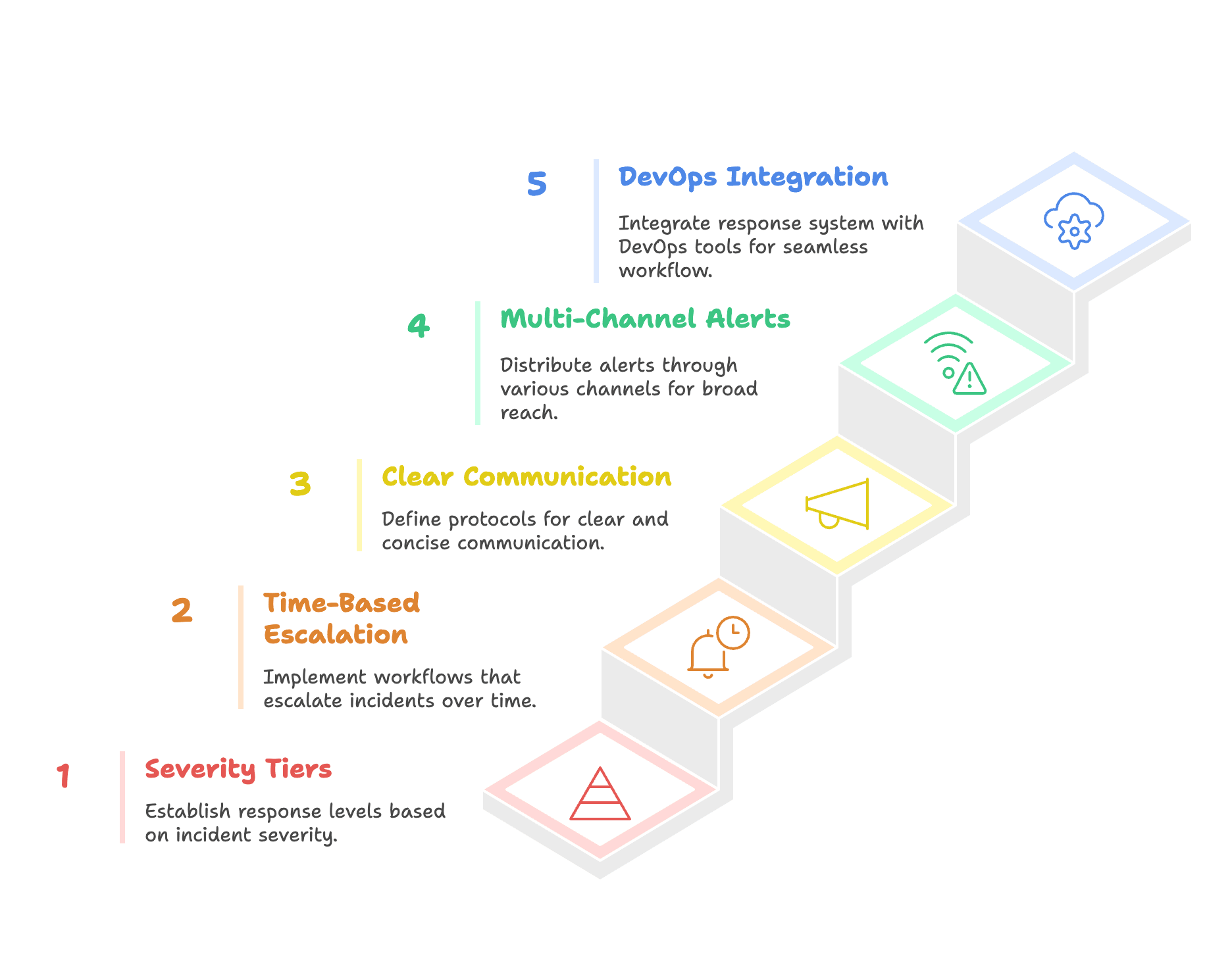
2. Key Components of an Effective Escalation System
A strong escalation system needs clear, practical elements to keep your team on track. This section outlines the essentials for SMEs using uptime monitoring in a simple table.
| Component | What It Does | Example |
|---|---|---|
| Severity-Based Response Tiers | Sorts incidents by impact to prioritize action. | Website down (Severity 1) gets instant attention; slow API (Severity 3) can wait. |
| Time-Based Escalation Workflows | Sets response deadlines to avoid delays and alert fatigue. | 5 minutes to acknowledge a critical alert, 15 minutes to escalate if unresolved. |
| Clear Communication Protocols | Uses standard templates for fast, clear handoffs. | “Service X down, Severity 1, assigned to [Name]” saves time in a crisis. |
| Multi-Channel Alert Distribution | Delivers alerts where your team is—Slack, email, SMS, etc. | Slack for devs, SMS for on-call staff, powered by tools like Bubobot. |
| Integration with DevOps Tools | Connects escalation to tools like PagerDuty, OpsGenie, and Bubobot’s server monitoring. | A failed heartbeat check in Bubobot triggers PagerDuty instantly. |
Pro Tip: Test these components quarterly to ensure they fit your team’s workflow.
3. How Bubobot Enhances Your Escalation Process
Bubobot supercharges your escalation with AI and practical features tailored for SMEs. Here’s how it boosts uptime monitoring and gets the right people fixing issues fast.
Faster Response Times: AI-driven monitoring reduces detection-to-resolution time
Bubobot’s AI spots problems—like an system downgrade—in seconds, not minutes, kicking off escalations instantly to shrink downtime.
Seamless DevOps Integration: Works with chat tools, incident management platforms, and automation workflows
It syncs with Slack, OpsGenie, and more, so alerts flow right into your team’s daily tools—no app-switching required.
Smart Escalation Routing: Reduces noise while ensuring critical issues get immediate attention
Bubobot filters out false alerts and, for emergencies, uses SMS and call alerts to wake up the right person—ensuring someone’s always on it, even at 3 a.m., to tackle critical incidents fast.
Key Takeaway: Bubobot’s smart routing and SMS/call alerts mean no emergency slips through the cracks.
4. Best Practices for Balancing Automation and Human Oversight
Automation speeds up responses, but humans add the context SMEs need for critical systems. Follow this step-by-step checklist to balance AI and human roles effectively with uptime monitoring.
Step 1: Map AI Alerts to Simple Issues
Assign AI to handle clear-cut problems—like a server ping failure—where fast detection is key. Keep it quick: if Bubobot flags a port down, it escalates instantly, no human delay needed.
Step 2: Reserve Complex Issues for Humans
Tag tricky incidents—like inconsistent Kafka availability—for human review. Set a rule: AI alerts the team, but a technical leader decides the fix within 15 minutes to avoid guesswork.
Step 3: Automate Initial Root Cause with a Human Check
Let AI suggest causes—like Bubobot spotting “high CPU load” for a slowdown—but require an IT admin to confirm within 10 minutes. This catches errors before they spiral.
Step 4: Set Time-Based Escalation Triggers
Build a timeline: AI escalates urgent alerts (e.g., website down) in 5 minutes, but waits 30 minutes for less critical ones (e.g., slow DNS) until a DevOps engineer weighs in.
Step 5: Pair AI Anomaly Detection with Human Insight
Use Bubobot’s AI to detect oddities—like an MQTT latency spike—and notify the team. Then, have a human assess: “Is this a real problem?” within 20 minutes to keep critical systems safe.
Pro Tip: Soon, Bubobot’s AI agents will learn your business context from historical data—like project instructions—figuring out which alerts suit AI handling and which need a human touch, making your balance even sharper.
5. Measuring Success & Continuously Improving Your Escalation Policies
You can’t improve what you don’t measure. This section shows how to track and refine your escalation setup using uptime monitoring data.
Key Metrics to Track: Mean Time to Detect (MTTD), Mean Time to Resolve (MTTR), false alert rates
MTTD under 5 minutes? MTTR below 30? Low false alerts? These signal a healthy policy. Bubobot’s dashboard makes this easy to monitor.
Post-Incident Reviews: Learning from past escalations to refine workflows
After a downtime event, ask: Did the right people get alerted? Was the fix fast enough? Adjust based on answers.
Using Uptime Monitoring Data: Identifying trends and preventing recurring issues
Spot patterns—like frequent SSL expirations—in Bubobot’s logs. Fix the root cause before it repeats.
Scaling Escalation Strategies: Adapting policies as infrastructure and monitoring needs evolve
As your SME grows, add tiers or channels to your policy. Bubobot’s server monitoring scales with you, keeping pace with new systems.
Key Takeaway: Measure, learn, and adapt—your escalation policy should evolve with your business.



