
Understanding website uptime benchmarks—from 99.9% to 99.999%—helps you set appropriate SLAs.
Whether you're running an e-commerce platform, SaaS application, or corporate site, understanding website uptime monitoring is crucial for maintaining customer trust and operational success. Let's dive into what uptime really means for your business and why those percentage points matter more than you might think.
1. Introduction to Website Uptime
Website uptime represents the time your site is accessible and functioning properly. It's the digital equivalent of keeping your store's doors open for business, and in our always-connected world, those doors need to stay open 24/7.
What is website uptime, and how is it measured?
Uptime is typically expressed as a percentage of time your website or service is operational and accessible. For example, 99.9% uptime means your site should be available 99.9% of the time within a given period. Uptime monitoring tools track this by regularly sending requests to your website or server and recording whether those requests succeed or fail.
Most monitor uptime solutions work by sending periodic HTTP requests to your website from various locations. If these checks fail, the system triggers alerts based on predefined conditions. Advanced uptime monitoring tools like Bubobot go beyond simple ping tests by checking entire user journeys, API endpoints, and even specific page components.
Why does uptime matter for businesses?
The importance of uptime extends far beyond technical metrics—it directly impacts your business health:
- Revenue Impact: For e-commerce sites, every minute of downtime equals lost sales. Amazon, for instance, reportedly loses about $220,000 per minute when their site goes down.
- Customer Trust: When users repeatedly encounter a down site, they lose confidence in your brand. A study by Akamai found that 79% of online shoppers who experience performance issues won't return to shop at that site.
- SEO Consequences: Search engines like Google factor site reliability into their ranking algorithms. Frequent outages can hurt your visibility in search results.
- Employee Productivity: For internal systems, downtime can leave your team unable to perform critical tasks, creating a ripple effect through operations.
Common causes of downtime and how they affect performance
Understanding what causes downtime helps you prevent it. Here are the most common culprits and their impacts:
| Cause of Downtime | Description | Business Impact |
|---|---|---|
| Server Overload | Traffic spikes exceeding infrastructure capacity | Slow page loads, complete unavailability during peak sales periods |
| Network Issues | Problems with DNS, ISPs, or routing | Site appears down for some or all users, often intermittently |
| Software Bugs | Errors in application code or CMS updates | Functionality breakdowns, security vulnerabilities |
| Database Failures | Corruption, connectivity issues, query problems | Data-dependent features fail, checkout processes break |
| Cyber Attacks | DDoS attacks, malicious activities | Complete service disruption, potential data breaches |
| Scheduled Maintenance | Planned downtime for updates | Controlled disruption, typically during low-traffic periods |
Each of these issues creates different patterns of downtime, which is why comprehensive monitor uptime solutions need to check multiple components of your system, not just whether your homepage loads.
Pro Tip: While aiming for 100% uptime might seem ideal, it's often unrealistic and unnecessarily expensive. Understanding your specific business requirements will help you set appropriate uptime targets that balance reliability with cost-effectiveness.
2. Industry Standards and Uptime Benchmarks
When discussing uptime goals, you'll often hear terms like "five nines" or "three nines" reliability. These benchmarks serve as reference points, but what's right for your business depends on several factors unique to your situation.
What are the common uptime benchmarks (99.9%, 99.99%, 99.999%)?
The industry typically recognizes several standard uptime tiers:
- 99.9% (Three Nines): Allows for 8.76 hours of downtime per year
- 99.95%: Allows for 4.38 hours of downtime per year
- 99.99% (Four Nines): Allows for 52.56 minutes of downtime per year
- 99.999% (Five Nines): Allows for just 5.26 minutes of downtime per year
Each additional "nine" reduces your allowed downtime by a factor of 10, making it exponentially more difficult and expensive to achieve. This is why implementing robust uptime monitoring becomes increasingly critical as your reliability requirements increase.
Downtime allowance per year for different uptime levels
To put these percentages in perspective, here's what they mean in terms of actual downtime:
| Uptime Percentage | Downtime Per Year | Downtime Per Month | Downtime Per Week |
|---|---|---|---|
| 99% | 3.65 days | 7.31 hours | 1.68 hours |
| 99.9% | 8.76 hours | 43.8 minutes | 10.1 minutes |
| 99.99% | 52.56 minutes | 4.38 minutes | 1.01 minutes |
| 99.999% | 5.26 minutes | 26.3 seconds | 6.05 seconds |
When setting up your uptime website monitoring strategy, these figures help you determine what level of reliability makes sense for your business needs.
Industry-specific uptime expectations (e-commerce, SaaS, finance, healthcare)
Different industries have varying uptime requirements based on their business models and regulatory environments:
| Industry | Typical Uptime Target | Downtime Impact | Special Considerations |
|---|---|---|---|
| E-commerce | 99.9% to 99.99% | $5,600+ per minute for mid-sized retailers | Higher targets during holiday seasons; checkout process requires greater reliability than product pages |
| SaaS Providers | 99.95% to 99.99% | Customer churn, contract penalties | Enterprise clients often negotiate custom SLAs; tier services by criticality |
| Financial Services | 99.99% to 99.999% | Regulatory violations, transaction failures | Subject to compliance requirements; often needs georedundant infrastructure |
| Healthcare | 99.99%+ for critical systems | Patient safety risks, compliance issues | Life-critical systems require redundant infrastructure; subject to HIPAA/GDPR requirements |
| Media & Entertainment | 99.9% to 99.99% | Subscriber dissatisfaction, ad revenue loss | Higher expectations during major events; streaming quality degradation matters as much as complete outages |
| Small Business Websites | 99.9% | Brand reputation impact | Often balance cost vs. reliability needs |
Key Takeaway: Don't just copy another company's uptime target—assess the real impact of downtime on your specific business operations and customer experience, then set appropriate goals and implement uptime monitoring tools that match those needs.
3. SLAs and Compliance for Website Uptime
Service Level Agreements (SLAs) formalize your uptime commitments and set clear expectations with customers, partners, and internal stakeholders. A well-crafted SLA protects both parties and creates transparency around service quality.
Understanding Service Level Agreements (SLAs) and their role in uptime guarantees
An SLA is essentially a promise about the level of service you'll deliver, with specific metrics and consequences if those standards aren't met. For websites and online services, uptime is typically a central component of these agreements.
SLAs serve several important functions:
- They clearly define what constitutes acceptable service
- They establish mutual understanding between service providers and customers
- They create accountability through defined penalties for non-compliance
- They help prioritize IT resources based on business-critical services
When drafting uptime SLAs, it's critical to have reliable uptime monitoring in place—you can't guarantee what you can't measure. Tools like Bubobot provide the continuous monitoring and historical reporting needed to verify SLA compliance.
Key SLA components: uptime percentage, penalties, and response time
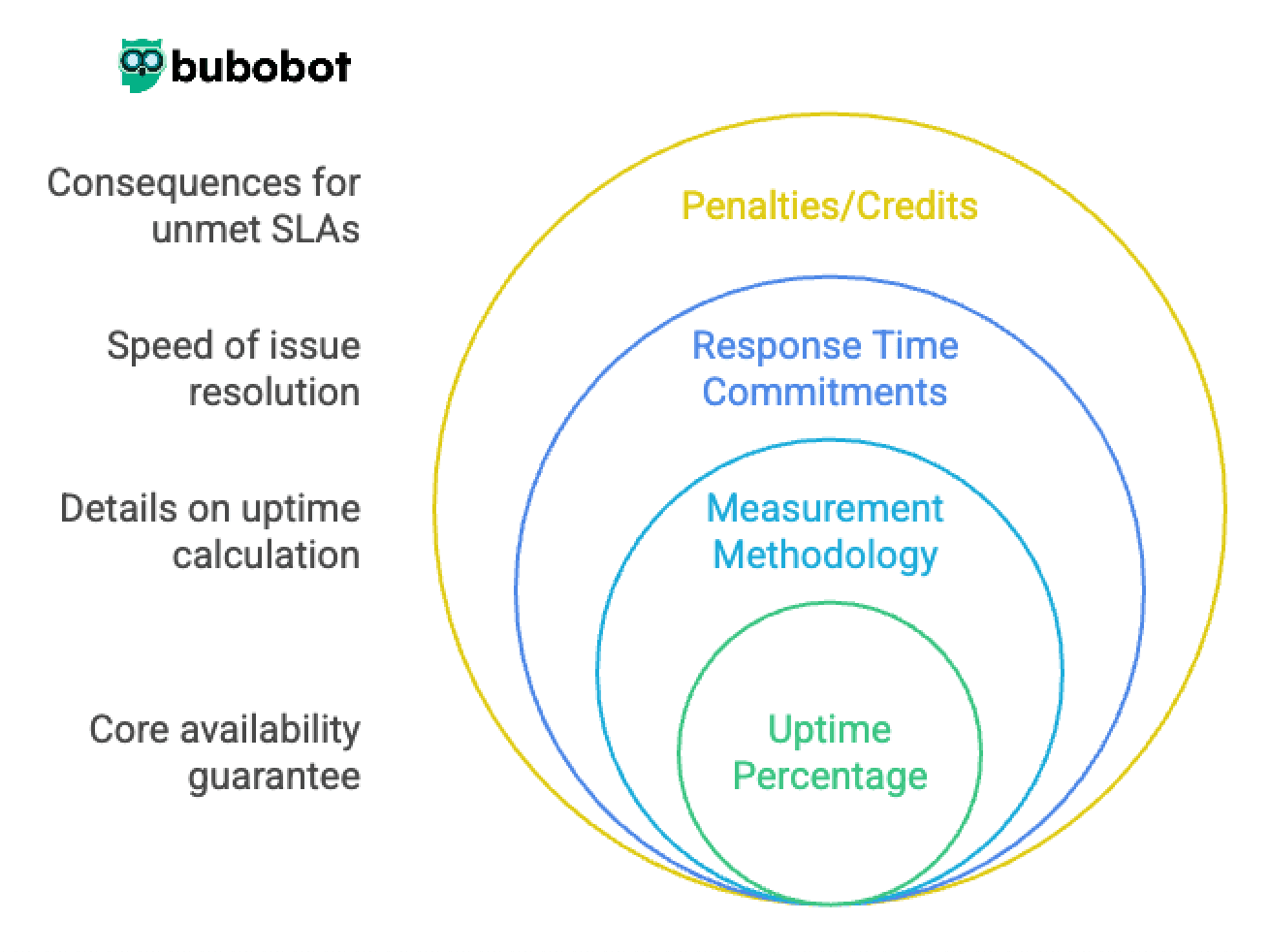
Effective uptime SLAs typically include these essential elements:
| SLA Component | Description | Why It Matters |
|---|---|---|
| Uptime Percentage | Guaranteed availability (e.g., 99.9%), measured monthly/quarterly | Sets clear performance expectations for all parties |
| Measurement Methodology | How uptime is calculated, including check frequency, locations, and failure criteria | Prevents disputes by establishing objective measurement standards |
| Exclusions | Events not counted as downtime (scheduled maintenance, customer-caused issues, force majeure) | Protects provider from penalties for unavoidable or planned outages |
| Response Time Commitments | How quickly issues will be acknowledged based on severity | Ensures rapid attention to critical problems |
| Resolution Time Targets | Expected timeframes for resolving different types of issues | Sets expectations for how quickly service will be restored |
| Penalties/Credits | Financial or service credits awarded when SLAs aren't met | Creates accountability and provides customer compensation |
| Reporting | How and when uptime statistics will be shared | Builds trust through transparency and verification |
Using dedicated uptime monitoring software ensures you have accurate, third-party verified data to demonstrate compliance with these commitments.
How to align SLAs with business goals and risk management
The best SLAs balance technical reality with business needs. Here's how to create meaningful uptime guarantees:
- Assess the true cost of downtime for each system to determine appropriate uptime targets. A marketing website might only need 99.9% uptime, while your checkout process requires 99.99%.
- Consider peak business periods when downtime would be especially damaging, and adjust your SLAs to reflect these critical windows.
- Review historical performance data from your web uptime monitoring tools before finalizing commitments.
- Establish clear communication protocols for downtime incidents, including notification channels and update frequency (or using Bubobot’s status page).
Pro Tip: Rather than creating a one-size-fits-all SLA, consider implementing tiered service levels that allow customers to choose the uptime guarantees that match their business needs—with corresponding pricing that reflects the cost of delivering higher reliability.
4. Achieving Optimal Uptime: A Step-by-Step Checklist
Reaching and maintaining your uptime targets requires a systematic approach spanning infrastructure design, monitoring, and operational practices. Here's a comprehensive roadmap to help you achieve optimal uptime reliability.
Phase 1: Define Business Requirements & Set Target SLA
Before investing in technical solutions, you need clarity on what level of uptime your business truly requires.
Identifying critical systems that need maximum uptime
Not all systems have equal importance. Categorize your applications and services based on:
- Revenue impact if unavailable
- Customer-facing vs. internal use
- Regulatory requirements
- Interdependencies with other systems
Setting realistic uptime goals based on industry benchmarks
Use the industry standards discussed earlier as starting points, then adjust based on:
- Competitive analysis of similar services
- Customer expectations in your market
- Cost/benefit analysis of each reliability tier
- Technical feasibility given your current infrastructure
Determining acceptable downtime and risk tolerance
Calculate what specific downtime windows mean for your business:
- What's the cost of 1 hour of downtime for each system?
- Are there times when downtime has minimal impact?
- What level of performance degradation is acceptable before it's considered "down"?
Document these decisions to guide your technical implementation and SLA definitions.
Phase 2: Design a High-Availability Architecture
With clear requirements established, you can design an infrastructure that supports your uptime goals.
Choosing between single-region vs. multi-region deployment
- Geographic distribution of your users
- Regulatory requirements for data residency
- Budget constraints
- Latency requirements
Implementing redundancy: load balancers, failover servers, cloud scaling
- Load Balancers: Distribute traffic and provide failover capability
- Application Servers: Deploy multiple instances across availability zones
- Auto-scaling: Automatically adjust capacity based on demand
- Database Clustering: Implement primary-secondary replication
- Network Redundancy: Multiple internet connections and providers
Optimizing database replication and storage for reliability
- Implement automated backups with point-in-time recovery
- Set up read replicas to distribute database load
- Consider multi-master configurations for critical systems
- Monitor replication lag and failover capabilities
- Implement connection pooling to handle traffic spikes
Phase 3: Implementing Real-Time Monitoring & Alerts
Even the best-designed systems fail eventually. The key to maintaining high uptime is detecting and responding to issues quickly.
How does Bubobot help with website, server, and service monitoring?
Comprehensive uptime monitoring requires visibility across multiple layers:
Bubobot provides a unified monitoring solution that covers:
- HTTP monitors for websites, APIs, and web applications
- Server monitoring including ping, port availability, and resource utilization
- SSL certificate monitoring to prevent unexpected expirations
- DNS monitoring to detect configuration issues
- Service-specific monitoring for technologies like Kafka and MQTT
The platform's AI-powered anomaly detection can identify subtle degradations before they become outages, giving your team time to intervene before users are affected.
The role of AI-driven anomaly detection in predicting downtime
Traditional threshold-based monitoring often misses subtle indicators of impending failures. Modern uptime monitoring tools like Bubobot use machine learning to:
- Establish normal baseline performance patterns
- Detect unusual trends that may indicate developing problems
- Reduce false positives by understanding contextual variations
- Predict potential failures before they occur
Configuring proactive alerts for performance degradation
Effective alerting is the bridge between monitoring and action:
- Define clear severity levels for different types of issues
- Establish appropriate notification channels for each severity (email, SMS, chat integrations)
- Implement alert routing to ensure the right team members are notified
- Set up escalation paths for unacknowledged alerts
- Create runbooks linked to specific alert types to guide response
With Bubobot's customizable alerting system, you can ensure that the right people get notified about potential issues with enough context to take immediate action.
Phase 4: Disaster Recovery Planning
Even with preventive measures, major incidents will eventually occur. Having a well-tested disaster recovery plan minimizes their impact.
Creating a structured disaster recovery plan
A comprehensive disaster recovery plan includes:
- Documented procedures for common failure scenarios
- Clear roles and responsibilities during outages
- Communication templates for internal and external updates
- Escalation paths for different incident types
Your plan should be detailed enough to guide recovery even if key personnel are unavailable.
Best practices for testing failover systems and incident response
A disaster recovery plan is only effective if it works when needed:
- Simulate various failure scenarios, not just complete outages
- Include third-party dependencies in your testing
- Practice communication processes during simulated incidents
Many organizations discover critical gaps in their recovery plans during these tests, making them invaluable for improving reliability.
Key Takeaway: Achieving high uptime requires a holistic approach spanning architecture, monitoring, and operational practices. Implementing comprehensive uptime monitoring with tools like Bubobot provides the visibility needed to maintain reliability and quickly resolve inevitable issues.
5. Conclusion: Ensuring Long-Term Website Uptime
Maintaining consistent uptime isn't a one-time project but an ongoing commitment requiring vigilance, continuous improvement, and the right tools. Let's recap the essential elements of an effective uptime strategy.
Key takeaways for maintaining uptime reliability
- Be realistic about your uptime needs: Target the appropriate level of reliability based on business impact, not arbitrary industry standards.
- Invest in redundancy where it matters most: Focus your high-availability investments on the most critical components of your infrastructure.
- Implement comprehensive monitoring: You can't fix what you don't know is broken. Uptime monitoring tools provide the visibility needed to maintain reliability.
- Develop and test recovery procedures: Even with the best prevention, failures will occur. Having well-tested recovery plans minimizes their impact.
How Bubobot supports businesses in uptime monitoring and risk prevention
Maintaining optimal uptime requires specialized tools designed for the task. Bubobot provides a comprehensive uptime monitoring solution tailored to modern web applications and infrastructure:
- Comprehensive coverage: Monitor websites, servers, APIs, and specialized services from multiple locations worldwide
- Customizable alerting: Ensure the right people get notified about potential issues
- Short interval checks: Detect issues faster with industry-leading monitoring frequency
- Integration flexibility: Connect with your existing tools and workflows
By implementing Bubobot's uptime monitoring solution, businesses gain the visibility and early warning capabilities essential for maintaining the reliability their customers expect.



