How Tech Giants Design Their Hyper-Resilient System (Part 1)

1. Introduction: The Shift Towards Modern Reliability Engineering
In overall, for reliability, Tech giants like Netflix and Facebook focus on proactive testing, automated recovery, and distributed architectures that eliminate single points of failure.
This article explores how these tech giants build bulletproof systems, the tools they use, and practical ways smaller teams can implement similar strategies with limited resources.
Key Takeaway: Tech giants have redefined reliability by designing systems that anticipate failures and recover automatically—without human intervention.
2. How Netflix Builds a Hyper-Resilient System
Netflix’s approach to reliability is centered around designing a system that can handle failures gracefully and recover quickly.
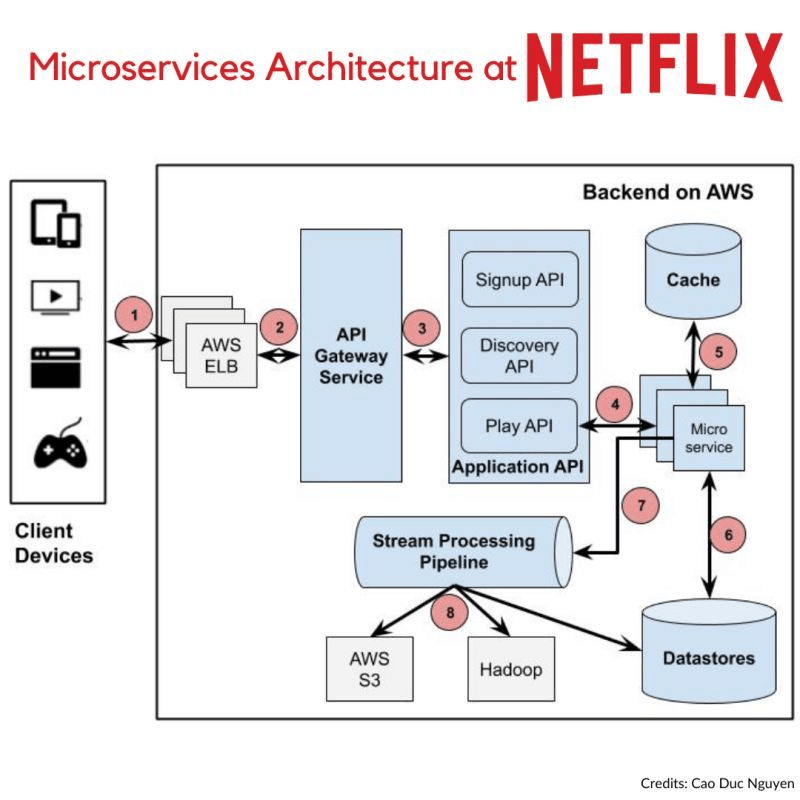
Core Architecture Design:
- Multi-Region Cloud Strategy: Netflix operates across multiple AWS regions to ensure geographical redundancy.
- Stateless Microservices: Netflix's architecture is composed of hundreds of small, independent services with no shared state.
- Edge-Based Content Delivery: Through its Open Connect CDN, Netflix distributes content from over 1,000 locations worldwide.
- Regional Isolation: Each region operates independently, preventing cascading failures that could spread across the entire system.
Netflix's Key Reliability Features:
| Feature | Description | Importance | Tools/Technologies |
|---|---|---|---|
| Chaos Engineering | Simulates failures in a controlled environment to test system resilience. | Ensures systems can survive real-world failures. | Chaos Monkey, FIT, ChAP |
| Distributed Microservices | Hundreds of small, independent services with no shared state. | Improves fault isolation and scalability. | Spinnaker, Eureka, Hystrix |
| Automated Failover | Redirects traffic during outages to maintain service availability. | Ensures continuous availability. | AWS Route 53, Zuul, Ribbon |
| Self-HealingInfrastructure | Uses automated remediation to handle and recover from failures. | Reduces manual intervention and response time. | Asgard, Atlas, Titus |
Netflix's Notable Technologies
Netflix's approach to reliability is centered on building systems that can withstand and recover from failures, leveraging a suite of notable technologies:
- Chaos Engineering:
- Chaos Monkey: Randomly terminates instances in production to ensure services are resilient to instance failures. It is part of Netflix's Simian Army, open-sourced for others to adapt (Chaos Monkey GitHub).
- FIT and ChAP: FIT (Failure Injection Testing) and ChAP (Chaos Automation Platform) extend chaos testing to microservice levels and automate experiments, respectively. Recent updates, as of June 2024, include ChAP's integration for broader chaos scenarios (Chaos Engineering – Netflix TechBlog).
- Distributed Microservices:
- Spinnaker: A continuous delivery platform for deploying and managing microservices, automating the deployment process (Netflix Open Source Software Center).
- Eureka: A service discovery tool that helps services locate each other, ensuring efficient communication in a distributed environment.
- Hystrix: A library providing circuit breakers and fallbacks, handling failures gracefully by isolating faulty services.
- Automated Failover:
- AWS Route 53: Amazon's DNS service with health checks, routing traffic to healthy endpoints, ensuring geographical redundancy (AWS Route 53 Documentation).
- Zuul: A gateway service providing dynamic routing and monitoring, configurable for failover scenarios.
- Ribbon: A client-side load balancer that retries requests or fails fast, enhancing failover at the application level.
- Self-Healing Infrastructure:
- Asgard: Manages and deploys applications on Amazon EC2, automating instance management (Netflix Open Source Software Center).
- Atlas: A monitoring and logging system providing real-time insights into system health, used for detecting issues.
- Titus: A container management platform for running microservices, enabling automated scaling and recovery.
- Contribution to Reliability: Automation in deployment and recovery ensures the system can self-correct, maintaining performance and availability.
Key Takeaway: Netflix's architecture is designed to thrive on failure, breaking and recovering seamlessly to maintain service continuity.
On the part 2 of this article, we’ll explore about Facebook approaches for system availability and reliability.
Please follow part 2 here: https://bubobot.com/blog/how-tech-giants-design-their-monitoring-strategy-part-2